
Recently, IBM researchers weighed in on container isolation, having developed an algorithm for measuring how well it works, and reached the conclusion that “a Docker container with a well crafted seccomp profile (which blocks unexpected system calls) provides roughly equivalent security to a hypervisor.“
This challenge of a “well crafted seccomp profile” is exactly what we’ve address with the Aqua CNAPP. But before we define what “well crafted” means, let’s explain syscalls and seccomp to the uninitiated reader.
If you already know this and want to see how Aqua 3.2 dynamically whitelists syscalls, enforces seccomp profiles and prevents kernel exploits, go right ahead and watch this short video:
Syscalls Explained
Linux system calls, or syscalls for short, are a set of 313 kernel-level commands that can be used by applications to get the operating system to provide various services and functions, from allocating memory resources, to creating a directory, to rebooting.
From a security standpoint, having open access to all syscalls represents a very large attack surface that can be used to exploit OS vulnerabilities and gain privileges on the host OS. Containers, which run in a shared kernel model, make use of syscalls and are therefore susceptible to these types of exploits.
Zero-day vulnerabilities like DirtyC0W (which we blogged about in late 2016) are often enabled through use of syscalls. DirtyC0W was a vulnerability that remained undisclosed for the better part of 11 years, and enabled an attacker to write arbitrary code into read-only files and directories, exploiting a flaw in how memory is managed in the kernel. SYS_PTRACE was the syscall used for this exploit.
What is seccomp?
Linux secure computing, or seccomp, provides a mechanism at the kernel level to only permit certain syscalls to be used. It uses a whitelisting approach, whereby activating seccomp denies all syscalls, only permitting those defined in a syscall profile.
So clearly, seccomp is a good idea. Indeed, many security experts (including us here at Aqua) recommend using seccomp profiles, but the challenge is in creating them and managing them. Back in 2016, Docker created a default seccomp profile for the Docker daemon, that disables 44 of the 313 syscalls, including SYS_REBOOT and SYS_PTRACE, to name a couple. For various reasons that I won’t get into here, this is not currently activated by default under Kubernetes.
The bigger issue is that even if you go with the default, it still leaves roughly 270 syscalls open, the vast majority of which will not be used by any given container app. In order to manually create a custom seccomp profile, you have to either be intimately familiar with how your app uses Linux kernel capabilities, or use a utility like strace (which, ironically, requires SYS_PTRACE to be enabled) to get a list of all syscalls actually used by your application. However, depending on the use-case, this might take a long time, and in reality most developers simply can’t be bothered with it. Reality on the ground is that very few organization bother with creating custom seccomp profiles for each and every application (or container). But what if there was an automated, hassle-free way to create custom seccomp profiles?
How Aqua Automates Syscall Profiling
We’ve extended our machine-learned behavioral profiling of containers to also include syscall use. Our model goes well beyond running a single container, and uses heuristics to determine not only what syscalls were used, but which ones are likely to be used. We’ve seen based on this that a typical container uses between 40 and 70 syscalls, so based on whitelisting those we can reduce the attack surface by as much as 80%-90%.
This approach provides significantly better reduction in the attack surface compared to seccomp profiles created based on application code analysis, which usually end up disabling many of the “obvious” syscalls, overlapping with the Docker default profile.
Our profiler usually takes a few minutes (occasionally longer) to profile a container, and the resulting whitelisted syscalls are visible – so this is not a “black box” solution. If the Image Profile is set to Enforce Mode, then only the whitelisted syscalls will be accessible to the container. Attempts to access other syscalls will be blocked using a custom seccomp profile attached to the container.
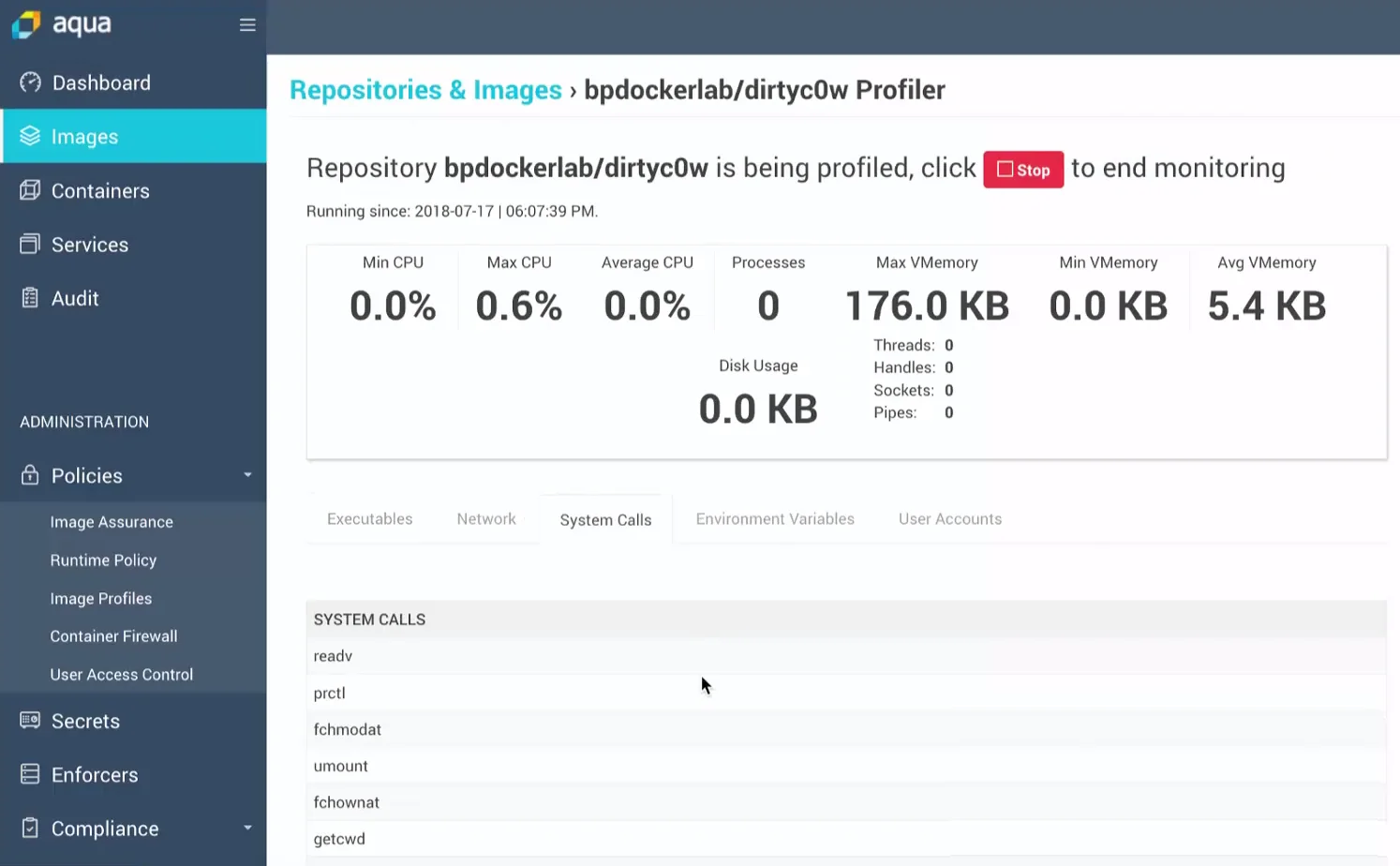
Back to Container Breakouts and Kernel Exploits
So how does this help? The issue of isolation (or lack thereof) between containers and their hosts has been discussed at length both here and elsewhere. There are several approaches to improve it, including sandboxing-type frameworks for containers, or hybrid VM-container constructs like Kata containers.
However, a tried and tested technology is already available, and that is seccomp. The challenge has been that custom seccomp profiles are hard to create manually, and have shown to be only marginally useful when applied based on static analysis of a container image. With dynamic profiling we can achieve much more dramatic results in reducing the number of available syscalls, while still ensuring the proper function of each container.
It’s a numbers game. We have no way of knowing what zero-day kernel vulnerabilities may be discovered tomorrow. We do know that many of them will use system calls to do their bidding and pwn the host OS, so reducing the number of available syscalls is an effective instrument in making it harder for attackers to leverage them, and preventing future exploits.
