
There has been plenty of buzz lately regarding an old-new privilege escalation vulnerability, adorably named “Dirty COW” after the Copy-On-Write memory protection in the Linux kernel. The whole thing started roughly eleven years ago, when a kernel developer left a race condition issue opened: “This is an ancient bug that was actually attempted to be fixed once (badly) by me eleven years ago”. The bug was eventually committed on October 18th 2016, and was quickly reported a day later as CVE-2016-5195. Shortly after, many public proof-of-concept codes popped up, demonstrating how one can write to readonly files, gain root access or even break out of a container.
At Aqua Security Research Labs we analyzed the impact of Dirty Cow on containers. Instead of rehashing explanations about how this exploit works, we’d like to focus on the core methods of exploitation out there, and how they affect containerized environments (if you would like to get a “behind-the-scenes” overview, start here).
Basically, this vulnerability relies on a race condition in the kernel. The race is between two operations: one performs writes to COW memory mappings, while the other continuously disposes of that memory. When this operation occurs over and over again, a race condition occurs, and the kernel may accidently write data to read-only memory mapping, instead of making a private copy first. And this is how a process is able to write data to protected memory – ouch!
In the wild, many proof-of-concept exploit codes have begun to pop up. They offer various flavors of privilege escalation techniques, such as patching an SUID file, writing shellcode to shared objects in memory etc. To be able to perform the exploit, the process must access its memory. It does so by either calling ptrace (which requires the SYS_PTRACE capability) or by opening its own memory like a “file” via /proc/self/mem. Because the SYS_PTRACE approach is less usable in containers (this capability is not added to containers by default), we will focus on the /proc/self/mem POCs and see if they pose any threat in containerized environments.
Seemingly, all the available POCs get root privileges by writing to files or memory objects in such a way that will only cause privilege escalation inside the container (one noteable exception is scumjr POC that patches vDSO, which requires the SYS_PTRACE capability). However, this can be misleading. To see why, let us perform a couple of easy demonstrations.
Writing Data into a Read-Only Mount
The simplest demonstration of this exploit would be showing how to write data to a write-protected file. To make this even more interesting, let’s perform a POC that writes data to a read-only mount from inside a container. A host can share files and directories with a container, with given restrictions such as read-only. If a container is able to write data to read-only files, it is effectively “breaking out”, modifying data that may be sensitive, or modifying files that will get it more privileges on the host.
First we need to check that we have a vulnerable kernel (you can check your kernel using this shell script):

To demonstrate the exploit I ran this code inside a container, from a non-root user (mike). The container was mounted to a read-only volume that contains a “protected” file:
$ docker run -it -v /root/readonlymnt:/home/mike/readonlymnt:ro dirtyc0wtainer
Even a root user should not have write access to a mapped read-only volume in a container (let alone a non-root user). However, as a result of the exploit we see that data indeed had been written to the file located in a read-only volume:
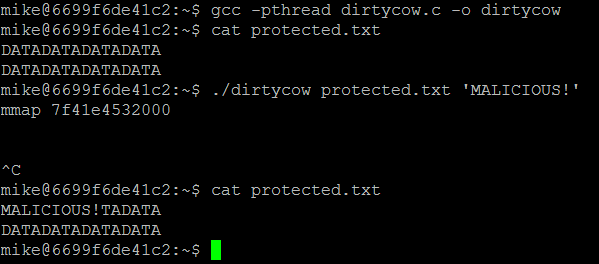
So that was neat: We just saw that it is possible to manipulate data on the host from within the container.
Running a Container with User Namespace
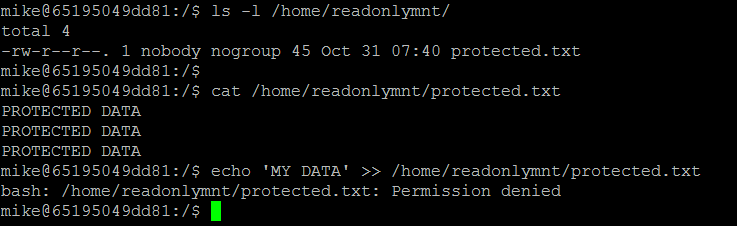
Now, let’s try add another layer of security: we will run a container with user namespace (by adding the --userns-remap="default" flag to the Docker daemon configuration), and also as a non-root user inside the container. When a container runs with user namespace, the root user inside the container is mapped to a non-root UID on the host. This means that even if an attack succeeds in getting a root user inside the container, it will effectively be a non-privileged user on the host. That sounds safer, right? Well yes, but because we are dealing with a kernel exploit, the answer is “not really”. In the following example, we will run a container in user namespace. The user inside the container will also be a non-root user (mike):
$ docker run -it -u mike -v /root/readonlymnt:/home/readonlymnt:ro dirtyc0wtainer /bin/bash
When we list processes on the host, we see that the shell is not running as root, but as uid 101001:

Inside the container, we are mike. Mike can read the protected data, but cannot write to it:
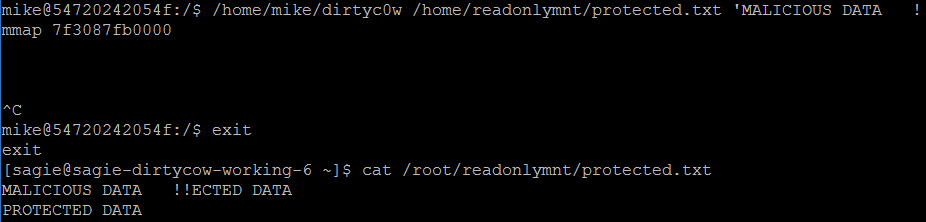
Now, as you probably guessed, I will run the exploit again and write to the protected file. When I exit the container and look at the file, it is (not surprisingly) changed:
Conclusion and Recommendations
In conclusion, when it comes to kernel vulnerabilities, you can’t be too careful. Containers still share the same kernel, which when exploited has the potential of jeopardizing other containers or the underlying host. We saw that a simple POC, which was not meant to break out of a container, could still modify data on the host.
So what should an admin do? It is always good practice to patch all of your hosts’ kernels. However, in the real world, this may not always be possible to do, or do fast enough. Apart from patching, it is crucial to make sure that your containers are being protected and monitored during runtime. Security products that provide runtime protection can be used to block specific system calls, limiting capabilities or access to certain files. These features allow you to virtually patch your containers, effectively mitigating the threat.