
Yesterday more than 300 cloud native professionals assembled for KubeSec, what has now become a fixture as a “day zero” event for KubeCon/CloudNativeCon. As with previous events, the emphasis was on end-user organizations’ experiences in securing production environments. While many technical aspects and best practices were covered, this year a recurring theme was tackling the organizational and cultural challenges that many participants had to overcome as part of this journey.

Are We There Yet?
This year KubeCon is taking place in San Diego, and is bigger than ever. This has also resulted in a multitude of “day zero” events on the Monday before the official conference starts. Nonetheless, we had no problem filling our hall at the Westin Gaslamp to the limit, thanks to a great lineup of talks and our co-sponsors AWS and Rancher. Here are some impressions, by no means exhaustive, of the day’s main themes.
There’s no shortage of technical challenges in this space.
Aqua co-founder and CTO, Amir Jerbi, gave a concise “attacker’s view” of Kubernetes – from API server access, to lateral movement, vulnerability exploitation, host escape, and data exfiltration – covering key countermeasures that should be taken to address these vectors. He was followed by our VP of Open Source Engineering, Liz Rice, showing a live demo of a new open-source tool Tracee, that uses eBPF to trace container syscall usage, but also how Aqua CSP can prevent unwanted syscalls upfront.
The topic of syscalls was revisited in the last talk of the day, by Grant Seltzer from Oscar Health, who explained the limited usability of seccomp profiles (to whitelist syscalls) for developers who never think of their applications in these terms, and offered help in the form of a classification of syscalls into more humanly comprehensible entitlements – under a project called Karn.
Identity, Identity
Authentication and authorization, RBAC, and identity management (for users and services) still seem to be complex challenges that can be addressed in many different ways – depending on the specific environment used, regulatory needs, security requirements, and sometimes preference.
Mike Ruth from Cruise Automation, the autonomous car company, spoke extensively about what you need to do to ensure proper AuthN and AuthZ in Kubernetes, and how you can bind roles to Google Cloud groups.
Marc Boorshtein from Tremolo Security spoke about implementing this in legacy environments, using Kerberos. What happens when you can’t break the legacy model, and you have no service account definitions in your identity management system? OPA (Open Policy Agent) to the rescue… it helps defining resource access in a way that translates the Kerberos model into Kubernetes.
How do you cluster your clusters?
Another aspect of Kubernetes environments that came up several times is how to scale clusters – whether using them “horizontally” to scale, i.e., deploying many clusters separated by applications, or using the multi-tenancy features of Kubernetes like namespaces, role bindings and network segmentation.
It seems that horizontally scaling clusters is the easier choice, as it provides isolation between apps and doesn’t require much effort, especially if you’re running managed cloud K8s clusters such as Amazon EKS, Azure AKS or Google GKE. This was outlined in the talk by Nir Valtman and Erik Skibicki from Finastra, and was also implied in the talk by Prachi Damle from Rancher, that showed an implementation of deploying Aqua’s kube-bench on multiple clusters and worker nodes.
On the flip side, Sajeev Rampal from Cisco, who’s also a member of the Kubernetes SIG on multi-tenancy, came back to KubeSec to elaborate on the work being done on multi-tenancy in Kubernetes. The current model is likely to be improved upon, and will prove particularly useful to those running K8s on bare metal, where running many small clusters would be inefficient and difficult to scale.
Organizational Challenges Exposed
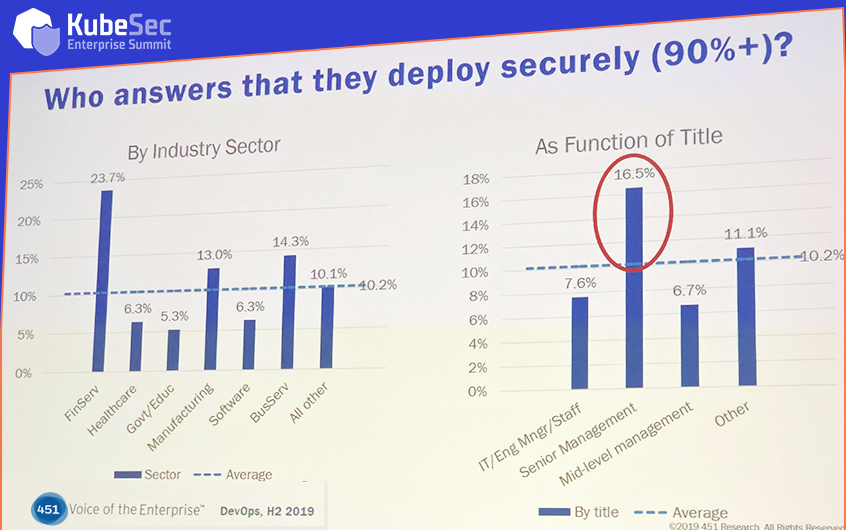
451 Research Group’s analyst Eric Hanselman provided many insights from the firm’s research and surveys of enterprise IT professionals. One slide that caught my attention (and chuckles from the audience) showed that, when asked whether they think they’re deploying cloud applications security, senior managers were more confident than those with “feet on the ground” (see below). This gap demonstrates the need for more education on the unique challenges of cloud at the higher levels. It also flies in the face of another finding, which is that spending on cloud deployment is growing faster than spending on cloud security, this despite security and data protection consistently appearing at the top of the list of cloud deployment challenges.
Danny DeChiara from JPMorgan Chase, in a “one year later” follow up talk to a talk JPMC gave in the first KubeSec, talked about how the bank faced challenges in addressing the needs of their environment: multiple independent Kubernetes clusters, each with its own users, use cases, workload types, tenancy structure and operating model running in production. He gave an honest self-assessment of the progress made, and not surprisingly some of the main challenges remain in collecting and understanding the various use cases, and better education on cloud and Kubernetes. Generally, the smoother aspects were those that were easy to automate, and the more challenging ones involved humans.
Ritu Sharma from Duke Energy gave a comprehensive overview of the company’s entire digital transformation journey, with a stack to support to multi-cloud and multi-datacenter deployment. She described the organizational aspect as a focus on AppDevInfraNetSecOps – a more comprehensive, if difficult to pronounce expansion of DevSecOps.

Perhaps the highlight of the day was the talk by Wes Kanazawa and Carlos Traitel from financial services company Primerica. It was both brutally honest in its depiction of the challenges of digital transformation in a regulated environment, as well as immensely entertaining and ultimately inspiring, since this transformation has been dramatically successful. From a “detect just before production, fix later” process they were successful in shifting left, automating testing and deployment, with faster cycle and far fewer manual inefficiencies.
With a full day of content, it’s a good thing we had a wall of donuts to start us off in the morning. This might become a staple of KubeSecs moving forward. And we’re gonna need a bigger wall.

See You in the next KubeSec Amsterdam!
The next KubeSec is already under way as a “day zero” event at KubeCon Europe.